

jpablo-norena
on 11 March 2024
Large Language Models (LLMs) Retrieval Augmented Generation (RAG) using Charmed OpenSearch
Improving the relevance of your LLM application by leveraging Charmed Opensearch’s vector database
Large Language Models (LLMs) fall under the category of Generative AI (GenAI), an artificial intelligence type that produces content based on user-defined context. These models undergo training using an extensive dataset composed of trillions of combinations of words from natural language, enabling them to empower interactive and conversational applications across various scenarios.
Renowned LLMs like GPT, BERT, PaLM, and LLaMa can experience performance improvements by gaining access to additional structured and unstructured data. This additional data may include public or internal documents, websites, and various text forms and content. This methodology, termed retrieval-augmented generation (RAG), ensures that your conversational application generates accurate results with contextual relevance and domain-specific knowledge, even in areas where the pertinent facts were not part of the initial training dataset.
RAG can drastically improve the accuracy of an LLM’s responses. See the example below:
“What is PRO?” response without RAG
Pro is a subscription-based service that offers additional features and functionality to users. For example, Pro users can access exclusive content, receive priority customer support, and more. To become a Pro user, you can sign up for a Pro subscription on our website. Once you have signed up, you can access all of the Pro features and benefits.
“What is PRO?” response with RAG
Ubuntu Pro is an additional stream of security updates and packages that meet compliance requirements, such as FIPS or HIPAA, on top of an Ubuntu LTS. It provides an SLA for security fixes for the entire distribution (‘main and universe’ packages) for ten years, with extensions for industrial use cases. Ubuntu Pro is free for personal use, offering the full suite of Ubuntu Pro capabilities on up to 5 machines.
This article guides you on leveraging Charmed OpenSearch to maintain a relevant and up-to-date LLM application.

What is OpenSearch?
OpenSearch is an open-source search and analytics engine. Users can extend the functionality of OpenSearch with a selection of plugins that enhance search, security, performance analysis, machine learning, and more. This previous article we wrote provides additional details on the features of OpenSearch. We discussed the capability of enabling enterprise-grade solutions through Charmed OpenSearch. This blog will emphasise a specific feature pertinent to RAG: utilising OpenSearch as a vector database.
What is a vector database?
Vector databases allow you to store and index, for example, text documents, rich media, audio, geospatial coordinates, tables, and graphs into vectors. These vectors represent points in N-dimensional spaces, effectively encapsulating the context of an asset. Search tools can look into these spaces using low-latency queries to find similar assets in neighbouring data points. These search tools typically do this by exploiting the efficiency of different methods for obtaining, for example, the k-nearest neighbours (k-NN) from an index of vectors.
In particular, OpenSearch enables this feature with the k-NN plugin and augments this functionality by providing your conversational applications with other essential features, such as fault tolerance, resource access controls, and a powerful query engine.
Using the OpenSearch k-NN plugin for RAG
IIn this section, we provide a practical example of using Charmed OpenSearch in the RAG process as a retrieval tool with an experiment using a Jupyter notebook on top of Charmed Kubeflow to infer an LLM.
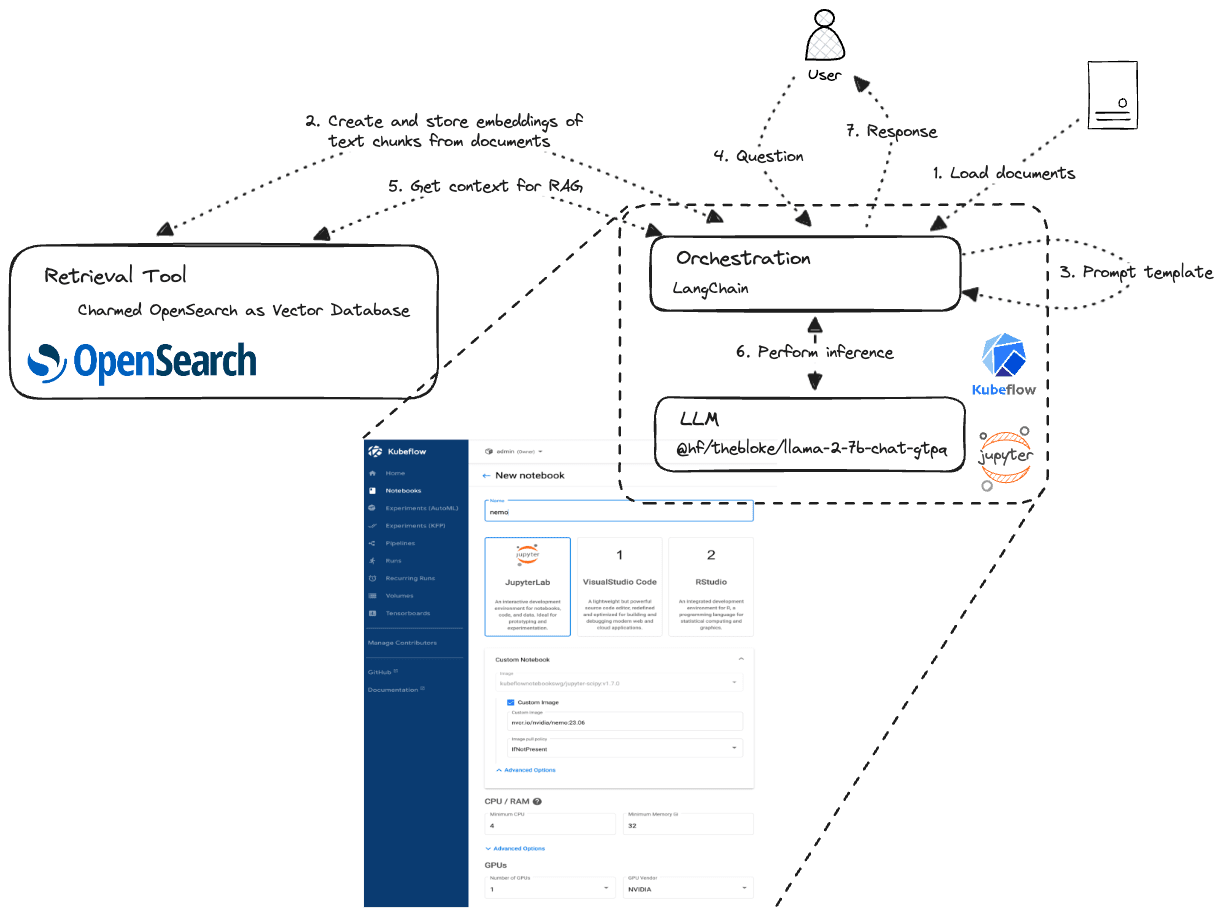
1. Deploy Charmed OpenSearch and enable the k-NN plugin. Follow the Charmed OpenSearch tutorial, which is a good starting point. At the end, verify if the plugin is enabled, which is enabled by default:
$ juju config opensearch plugin_opensearch_knn
true2. Get your credentials. The easiest way to create and retrieve your first administrator credentials is to add a relation between Charmed Opensearch and the Data Integrator Charm, which is also part of the tutorial.
3. Create a vector index for your k-NN index. Now, we can create a vector index for your additional documents encoded into the knn_vectors data type. For simplicity, we will use the opensearch-py client.
from opensearchpy import OpenSearch
os_host = 10.56.118.209
os_port = 9200
os_url = "https://10.56.118.209:9200"
os_auth = ("opensearch-client_7","sqlKjlEK7ldsBxqsOHNcFoSXayDudf30")
os_client = OpenSearch(
hosts = [{'host': os_host, 'port': os_port}],
http_compress = True,
http_auth = os_auth,
use_ssl = True,
verify_certs = False,
ssl_assert_hostname = False,
ssl_show_warn = False
)
os_index_name = "rag-index"
settings = {
"settings": {
"index": {
"knn": True,
"knn.space_type": "cosinesimil"
}
}
}
opensearch_client.indices.create(index=os_index_name, body=settings)
properties={
"properties": {
"vector_field": {
"type": "knn_vector",
"dimension": 384
},
"text": {
"type": "keyword"
}
}
}
opensearch_client.indices.put_mapping(index=os_index_name, body=properties)4. Aggregate source documents. In this example, we will select a list of web content that we want our application to use as relevant information to provide accurate answers:
content_links = [
https://discourse.ubuntu.com/t/ubuntu-pro-faq/34042
]5. Load document contents into memory and split the content into chunks. It will allow us to create the embeddings from the selected documents and upload them to the index we created.
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(content_links)
htmls = loader.load()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=0,
separator="\n")
docs = text_splitter.split_documents(htmls)6. Create embeddings for text chunks and store embeddings in the vector index. It will allow us to create the embeddings from the selected documents and upload them to the index we created.
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L12-v2",
encode_kwargs={'normalize_embeddings': False})
from langchain.vectorstores import OpenSearchVectorSearch
docsearch = OpenSearchVectorSearch.from_documents(docs, embeddings,
ef_construction=256,
engine="faiss",
space_type="innerproduct",
m=48, opensearch_url=os_url,
index_name=os_index_name,
http_auth=os_auth,
verify_certs=False)7. Use the similarity search to retrieve the documents that provide context to your query. The search engine will perform the Approximate k-NN Search, for example, using the cosine similarity formula, and return the relevant documents in the context of your question.
query = """
What is Pro?
"""
similar_docs = docsearch.similarity_search(query, k=2,
raw_response=True,
search_type="approximate_search",
space_type="cosinesimil")8. Prepare you LLM. We used a simple example using a HugginFace pipeline to load an LLM.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain.llms import HuggingFacePipeline
model_name="TheBloke/Llama-2-7B-Chat-GPTQ"
model = AutoModelForCausalLM.from_pretrained(
model_name,
cache_dir="model",
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(model_name,cache_dir="llm/tokenizer")
pl = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length = 2048.
)
llm = HuggingFacePipeline(pipeline=pl)9. Create a prompt template. It will define the expectations of the response and specify that we will provide context for an accurate answer.
from langchain import PromptTemplate
question_prompt_template = """
You are a friendly chatbot assistant that responds in a conversational manner to user's questions.
Respond in short but complete answers unless specifically asked by the user to elaborate on something.
Use History and Context to inform your answers.
Context:
---------
{context}
---------
Question: {question}
Helpful Answer:"""
QUESTION_PROMPT = PromptTemplate(
template=question_prompt_template, input_variables=["context", "question"]
)10. Infer the LLM to answer your question using the context documents retrieved from OpenSearch.
from langchain.chains.question_answering import load_qa_chain
question = "What is Pro?"
chain = load_qa_chain(llm, chain_type="stuff", prompt=QUESTION_PROMPT)
chain.run(input_documents=similar_docs, question=query)Conclusion
Retrieval-augmented generation (RAG) is a method that enables users to converse with data repositories. It’s a tool that can revolutionise how you access and utilise data, as we showed in our tutorial. With RAG, you can improve data retrieval, enhance knowledge sharing, and enrich the results of your LLMs to give more contextually relevant, insightful responses that better reflect the most up-to-date information in your organisation.
The benefits of better LLMs that can access your knowledge base are as obvious as they are alluring: you gain better customer support, employee training and developer productivity. On top of that, you ensure that your teams get LLM answers and results that reflect accurate, up-to-date policy and information rather than generalised or even outright useless answers.
As we showed, Charmed OpenSearch is a simple and robust technology that can enable RAG capabilities. With it (and our helpful tutorial), any business can leverage RAG to transform their technical or policy manuals and logs into comprehensive knowledge bases.
Enterprise-grade and fully supported OpenSearch solution
Charmed OpenSearch is available for the open-source community. Canonical’s team of experts can help you get started with it as the vector database to leverage the power of the k-NN search for your LLM applications at any scale. Contact Canonical if you have questions.
Watch the webinar: Future-proof AI applications with OpenSearch as a vector database



