Michelle Anne Tabirao
on 13 December 2024

In a 2020 paper, Patrick Lewis and his research team introduced the term RAG, or retrieval-augmented generation. This technique enhances generative AI models by utilizing external knowledge sources such as documents and extensive databases. RAG addresses a gap in traditional Large Language Models (LLMs). While traditional models rely on static knowledge already contained within them, RAG incorporates current information that serves as a reliable source of truth for LLMs. Although LLMs can rapidly understand and respond to prompts, without RAG, they often fall short in providing current or more specific information.
One practical application of RAG is in conversational agents and chatbots. RAG models enhance these systems by enabling them to fetch contextually relevant information from external sources. This capability ensures that customer service chatbots, virtual assistants, and other conversational interfaces deliver accurate and informative responses during interactions. Another use case is in advanced question-and-answer systems, where RAG models help individuals obtain answers to queries, such as support ticket responses. Additionally, RAG can be utilized in content recommendation systems, offering personalized recommendations by retrieving relevant information to enhance users’ experiences and content engagement.
Benefits of using RAG
Data sources that build trust
When using a machine learning model for enterprise applications, such as chatbots or for searching sensitive data, RAG provides the models with verifiable information that can be cited. This approach enables the models to focus on less ambiguous contexts, significantly reducing the likelihood of generating incorrect outputs – a phenomenon often referred to as “hallucination”.
Up-to-date information
With RAG, you can load current and reliable data, ensuring that your model will retrieve accurate information.
Simplicity of RAG
Lewis and three coauthors published a paper titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” in which they demonstrated RAG with just five lines of code. This implementation resulted in a model that includes a question encoder, a retriever, and a generator for context-aware answers. The simplicity of this implementation showcases that RAG is relatively easy as a concept and project. However, complexity does increase in production and large-scale deployments.
Reduced costs of continuous model re-training
Continuously re-training machine learning models can be expensive. By utilizing RAG, there is no need to depend on time-intensive and costly parameter retraining. This has the potential to lower both computational and financial costs associated with running LLM-powered chatbots in an enterprise setting.
How RAG works
When a query is made in an AI chatbot, the RAG-based system first retrieves relevant information from a large dataset or knowledge base, then this information is used to inform and guide the generation of the response. The RAG-based system consists of two key components. The first component is the Retriever, which is responsible for locating relevant pieces of information that can help answer a user query. It searches a database to select the most pertinent information. This information is then provided to the second component, the Generator. The Generator is a large language model that produces the final output. See the figure below:
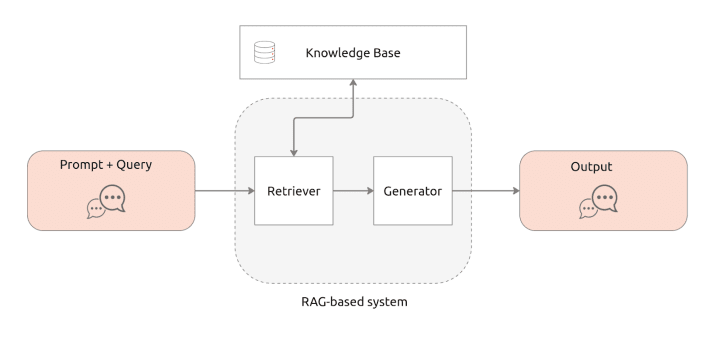
Before using your RAG-based system, you must first create your knowledge base, which consists of external data that is not included in your LLM training data. This external data can originate from various sources, including documents, databases, and API calls. Most RAG systems utilize an AI technique called model embedding, which converts data into numerical representations and stores it in a vector database. By using an embedding model, you can create a knowledge model that is easily understandable and readily retrievable in the context of AI. Once you have a knowledge base and a vector database set up, you can now perform your RAG process; here is a conceptual flow:

The RAG-based system has five straightforward steps:
- You can begin by entering your prompt or query.
- Retriever is used for searching for relevant information from a knowledge base. The relevance can be determined using mathematical vector calculations and representations through a vector search and database functionality.
- The relevant information to provide enhanced context is retrieved and passed to the generator.
- Query and prompts are now enriched with this context and are ready to be augmented for use with a large language model using prompt engineering techniques (LLM). The augmented prompt enables the language model to respond accurately to your query.
- Finally, the generated text response is delivered to you.
Canonical for your RAG requirements
Build the right RAG architecture with Canonical RAG workshop
Canonical offers a 5-day workshop designed to help you start building your enterprise RAG systems. By the end of the workshop, you will have a thorough understanding of RAG and LLM theory, architecture, and best practices. Together, we will develop and deploy solutions tailored to your specific needs.
Explore more and contact our team for your RAG needs.