

robgibbon
on 10 August 2023

I’ve read and watched more than a few articles about ChatGPT in the last couple of months. It seems the large language model AI hype machine just can’t stop. As somebody with a passion for music production, some of the more interesting things I’ve seen included a guy using ChatGPT to build a virtual effect plugin for his DAW (digital audio workstation) that emulates an Ibanez Tube Screamer guitar effects pedal, and this video about getting ChatGPT to write MIDI music scores using Python notebooks. As I’m working on bringing to market a solution for running Spark on Kubernetes, it got me thinking…
May the prompt be with you

Can I get ChatGPT to output a Spark job? Well there’s only one way to find out so I signed up for a ChatGPT account over at OpenAI and fired up a prompt. Feeling a bit like a naughty hacker, I was in. I typed in my command:
Write a pyspark job that ranks Linux distributions by popularity based on issues reported on stackoverflow
And the output immediately began spewing down my screen.

But now the $64k question. Will it work? Examining the output, it won’t work, because ChatGPT hasn’t provided us with code to scrape StackOverflow.com for the information we need.
Let’s see:
Write a pyspark job to scrape Stackoverflow for the Linux distribution issue report data used as input to the previous job
ChatGPT comes back with a python script (not a PySpark job, but OK) to scrape StackOverflow.com. So I fired up an editor and pasted it in. Perhaps needless to say, but StackOverflow seems to have changed its HTML layout template since the last time ChatGPT was trained, because the Python script didn’t work out of the box, and tweaks were needed.
When I was a kid in the early 1980s, publishers would sell computer magazines and books with code listings for games in BASIC that you could program into your ZX Spectrum yourself. Alas they were always full of bugs and would never run first time, and due to the unusual way code had to be input on a Spectrum, this usually meant spending a fair few hours inputting the commands before finding out. I’m getting the feeling that ChatGPT might be going the same way. Better get a cup of tea and a biscuit, I feel this is going to be a session.
ChatGPT vs hand edited script
Ok, nice try ChatGPT but this is going to need a bit of tweaking. I needed to change the target HTML entities and CSS classes that the script needs to find and process (and lightly restructure things). I’m able to scrape the data I need from StackOverflow. Here’s the original and the adapted code listings.
Original web scraper listing from ChatGPT
Corrected web scraper listing
Time to make some parallel, distributed sparks fly
Alright, so now we have the data we need, will that PySpark job that ChatGPT made us actually work? Let’s give it a whirl.
Well immediately, it won’t work because the fields in the CSV have different names from what the job expects. But that’s an easy tweak. Here’s ChatGPT’s listing, but adapted for my needs. That wasn’t as bad as I feared.
Adapted ChatGPT output PySpark job
The result
Drumroll please, time to find out which is the most popular distro:
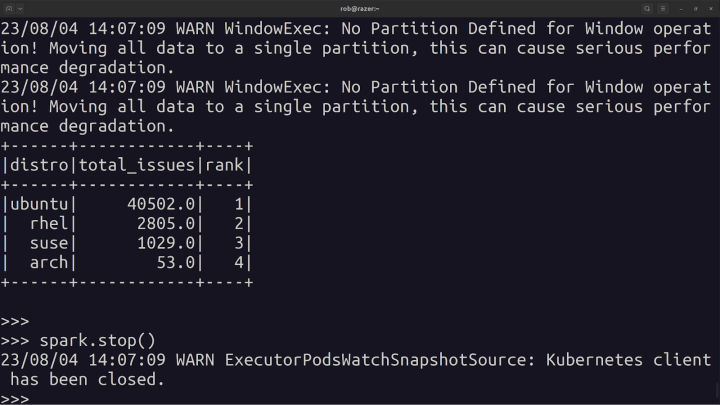
Of course no surprises: it’s Ubuntu that gets the most questions, because it’s Ubuntu that gets the most use.
In the end there were quite a few changes that I needed to make to get a working job, but clearly there’s potential for this technology, especially if you’re new to Spark and data engineering in general – it can give you a starter job quite quickly, but expect to make changes.
If you’re interested in Spark…
You might like to check out our Charmed Spark solution for running Spark on Kubernetes. We recently shipped the Beta and are looking for feedback.
To get started, visit the Charmed Spark documentation pages and install the spark-client snap.
Let us know what you think at https://chat.charmhub.io/charmhub/channels/data-platform or file bug reports and feature requests in Github.


