
OpenStack architecture
The best recipe for a successful cloud deployment is to follow a proven design guide from an experienced and trusted advisor. Canonical's reference architecture for OpenStack has been successfully deployed across hundreds of customers and thousands of sites.
Check the reference architecture
Is OpenStack complex?
Everyone who has any experience with OpenStack knows this feeling very well. You want to try it. You're committed to learning it. You even start exploring its documentation. But then, almost immediately, you are exposed to its complex architecture.
Tens of services, hundreds of processes, thousands of different configuration options: all of that to meet the needs of the most demanding industries, end users and their use cases. But do you really need all this overhead? What if all you need is your own general-purpose cloud?
Keep reading to learn how Canonical OpenStack helps you bypass all this complexity.

Why Canonical OpenStack?
If you want to use OpenStack, but don't necessarily want to deal with its internals, you're in the right place. Canonical effectively tames the complexity of the upstream OpenStack project and delivers its distilled excellence in the form of a human-friendly product — Canonical OpenStack.
Opinionated design
Canonical OpenStack includes active and stable services only, together with the major compute, network and storage options. This eliminates friction, ensures an enterprise-grade stability and provides an “on rails” user experience.
Cloud-native architecture
Canonical OpenStack comes with a fully cloud-native architecture based on Kubernetes, OCI images and snaps. This decouples OpenStack from the underlying Ubuntu OS and makes its updates and upgrades simple, straightforward and user-friendly.
Full bottom-up automation
Canonical OpenStack uses full bottom-up automation based on MAAS and Juju across all the layers of the stack. This covers the initial provisioning of physical machines, cloud bootstrap processes as well as its post-deployment operations.
High-level abstraction
Canonical OpenStack exposes a high-level interface for bootstrapping and operating the cloud. This effectively abstracts the complexity of the upstream project and enables users to spin up a cloud in just a few simple steps.
OpenStack under the hood
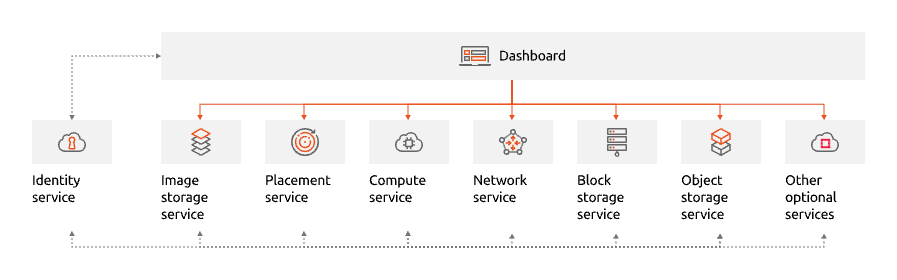
OpenStack uses a modular architecture with every service responsible for an individual cloud feature. This includes identity management, an image catalog as well as all the compute, network and storage functions that are typically required to provision and decommission virtual machines.
The services are further broken down into processes based on a microservices architecture. Each process implements an atomic cloud function, such as handling user requests, proxying database queries or invoking various types of backend technologies used by OpenStack underneath.
In order to minimize its footprint, Canonical OpenStack ships with only the key features enabled by default. Additional features, such as CaaS or a Load Balancer can be enabled post-deployment with a single terminal command.
Access supported features
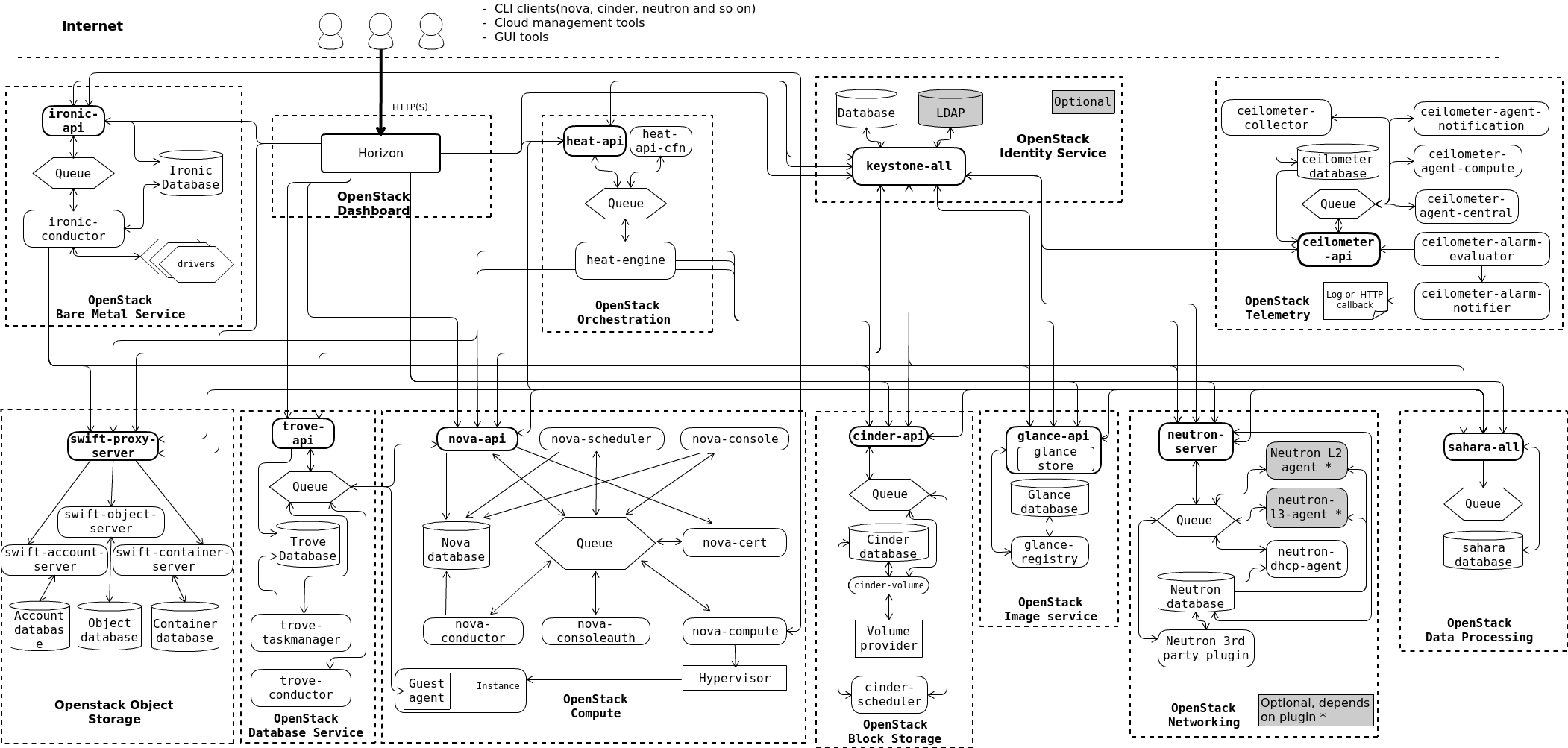
OpenStack components
- Services expose APIs and handle user requests
- Processes create a service and implement atomic cloud functions
- Dashboard provides a web-based user interface to services
- Client provides a command-line user interface to services
- Databases store various types of records created by services
- Queues facilitate communication between processes within a service

{kind=link}
How does it work?
In principle, OpenStack resembles the behavior of leading public clouds. Users can provision resources from their own pool through a self-service portal. All requests are handled by OpenStack itself in a fully automated way.
-
The user requests resources
OpenStack enables on-demand resource provisioning. This means that users can request them at any time through the client, dashboard or APIs. No admin intervention is required. No ticket is needed to process users' requests. Provisioning happens behind the scenes. OpenStack takes care of everything.
-
OpenStack handles the request
Depending on the type of a request, one or another service gets involved in its processing. Each service manages its own domain and provides all necessary functions to handle the given task. This includes user authentication, authorization, resource scheduling, metrics collection, etc.
Get started
with Canonical OpenStack
Are you ready for the next step? Get your own OpenStack instance up and running in just a few minutes.
With Canonical OpenStack you can get started on your journey on a single physical machine. Simply try it out and continue learning through some practical exercises.
Start today